1、构造函数
1.1 什么是构造函数
类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。
每次构造的是构造成员变量的初始化值,内存空间等。
构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值。
#include <iostream>
#include <string>
using namespace std; // 使用std命名空间
class Car {
public:
string brand; // 不需要使用std::string
int year;
// 无参构造函数
Car() {
brand = "未知";
year = 0;
cout << "无参构造函数被调用" << endl; // 不需要使用std::cout和std::endl
}
void display() {
cout << "Brand: " << brand << ", Year: " << year << endl;
}
};
int main() {
Car myCar; // 创建Car对象
myCar.display(); // 显示车辆信息
return 0;
}1.2 带参数的构造函数
默认的构造函数没有任何参数,但如果需要,构造函数也可以带有参数。这样在创建对象时就会给对象赋初始值。
#include <iostream>
#include <string>
using namespace std;
class Car {
public:
string brand;
int year;
// 带参数的构造函数,使用常规的赋值方式
Car(string b, int y) {
brand = b;
year = y;
}
void display() {
cout << "Brand: " << brand << ", Year: " << year << endl;
}
};
int main() {
Car myCar("Toyota", 2020); // 使用带参数的构造函数创建Car对象
myCar.display(); // 显示车辆信息
return 0;
}1.3 使用初始化列表
在C++中,使用初始化列表来初始化类的字段是一种高效的初始化方式,尤其在构造函数中。初始化列表直接在对象的构造过程中初始化成员变量,而不是先创建成员变量后再赋值。这对于提高性能尤其重要,特别是在涉及到复杂对象或引用和常量成员的情况下。
初始化列表紧跟在构造函数参数列表后面,以冒号( : )开始,后跟一个或多个初始化表达式,每个表达式通常用逗号分隔。下面是使用初始化列表初始化字段的例子:
class MyClass {
private:
int a;
double b;
std::string c;
public:
// 使用初始化列表来初始化字段
MyClass(int x, double y, const std::string& z) : a(x), b(y), c(z) {
// 构造函数体
}
};在这个例子中, MyClass 有三个成员变量: a ( int 类型)、 b ( double 类型)和 c
(1) 效率 :对于非基本类型的对象,使用初始化列表比在构造函数体内赋值更高效,因为它避免了先默 认构造然后再赋值的额外开销;
使用初始化列表是C++中推荐的初始化类成员变量的方式,因为它提供了更好的性能和灵活性。
1.4 拷贝构造函数
1.4.1 基本概念及发生条件
//其中, other 是对同类型对象的引用,通常是常量引用。
class MyClass {
public:
MyClass(const MyClass& other);
};#include <iostream>
#include <string>
using namespace std;
class Car {
public:
string brand;
int year;
// 常规构造函数
Car(string b, int y) : brand(b), year(y) {}
// 拷贝构造函数
Car(const Car& other) {
brand = other.brand;
year = other.year;
cout << "拷贝构造函数被调用" << endl;
}
void display() {
cout << "Brand: " << brand << ", Year: " << year << endl;
}
};
int main() {
Car car1("Toyota", 2020); // 使用常规构造函数
Car car2 = car1; // 使用拷贝构造函数
car1.display();
car2.display();
return 0;
}1.4.2 浅拷贝
浅拷贝只复制对象的成员变量的值。如果成员变量是指针,则复制指针的值(即内存地址),而不是指针所指向的实际数据。这会导致多个对象共享相同的内存地址。
#include <iostream>
using namespace std;
class Shallow {
public:
int* data;
Shallow(int d) {
//(d):这是初始化表达式。在这里,分配的 int 类型内存被初始化为 d 的值。如果 d 的值是20,那么分配的内存将被初始化为 20。
data = new int(d); // 动态分配内存
cout << "观察数据:" << endl;
cout << d << endl;
cout << *data << endl;
cout << "观察内存在构造函数中:" << endl;
cout << data << endl;
}
// 默认的拷贝构造函数是浅拷贝
~Shallow() {
delete data; // 释放内存
}
};
int main() {
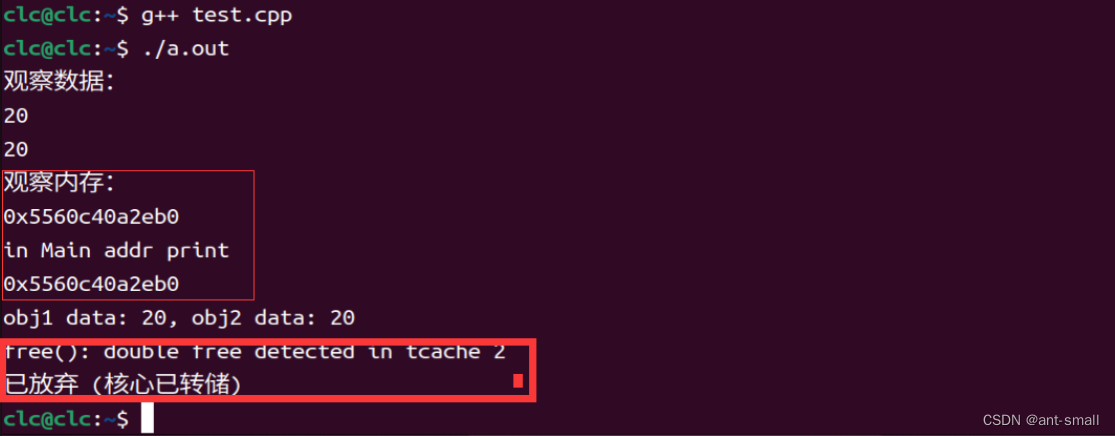
Shallow obj1(20);
Shallow obj2 = obj1; // 浅拷贝
cout << "观察内存在main函数obj2的data地址:" << endl;
cout << obj2.data << endl;
cout << "obj1 data: " << *obj1.data << ", obj2 data: " << *obj2.data << endl;
return 0;
}在这个例子中, obj2 是通过浅拷贝 obj1 创建的。这意味着 obj1.data 和 obj2.data 指向相同的内存地址。当 obj1 和 obj2 被销毁时,同一内存地址会被尝试释放两次,导致潜在的运行时错误。 在Linux中我们获得如下运行结果:
1.4.3 深拷贝
深拷贝复制对象的成员变量的值以及指针所指向的实际数据。这意味着创建新的独立副本,避免了共享内存地址的问题。
#include <iostream>
using namespace std;
class Deep {
public:
int* data;
Deep(int d) {
data = new int(d); // 动态分配内存
cout << "观察数据:" << endl;
cout << d << endl;
cout << *data << endl;
cout << "观察内存在构造函数中:" << endl;
cout << data << endl;
}
// 显式定义深拷贝的拷贝构造函数
Deep(const Deep& source) {
data = new int(*source.data); // 复制数据,而不是地址
cout << "深拷贝构造函数\n";
}
~Deep() {
delete data; // 释放内存
}
};
int main() {
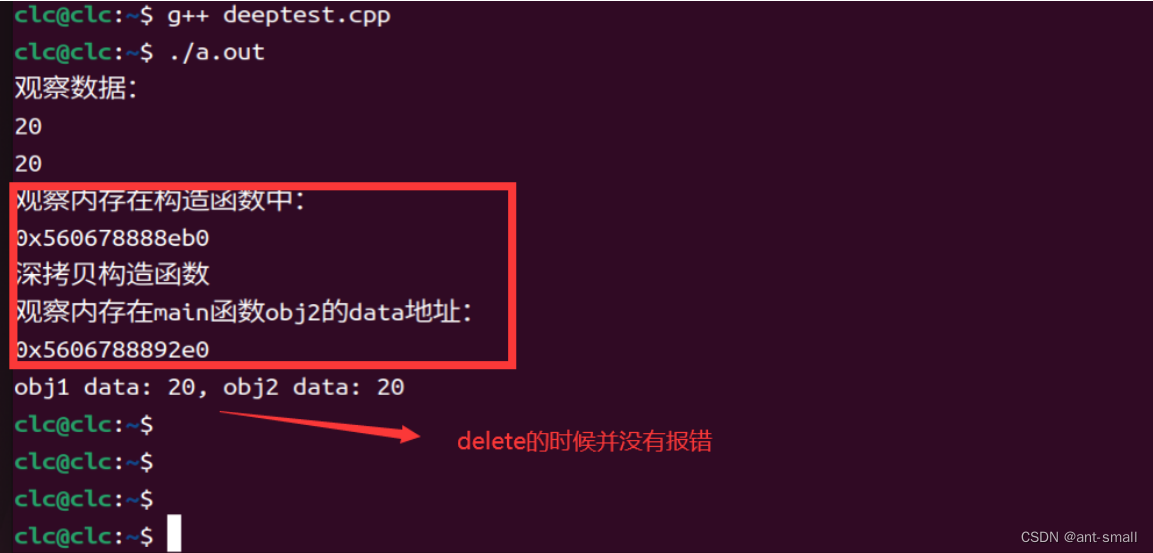
Deep obj1(20);
Deep obj2 = obj1; // 深拷贝
cout << "观察内存在main函数obj2的data地址:" << endl;
cout << obj2.data << endl;
cout << "obj1 data: " << *obj1.data << ", obj2 data: " << *obj2.data << endl;
return 0;
}在这个例子中, obj2 是通过深拷贝 obj1 创建的。这意味着 obj1.data 和 obj2.data 指向不同的内存地址。每个对象有自己的内存副本,因此不会相互影响,避免了潜在的运行时错误。
1.4.4 规则三则
在C++中,规则三则(Rule of Three)是一个面向对象编程原则,它涉及到类的拷贝控制。规则三则指出,如果你需要显式地定义或重载类的任何一个拷贝控制操作(拷贝构造函数、拷贝赋值运算符、析构函数),那么你几乎肯定需要显式地定义或重载所有三个。这是因为这三个功能通常都是用于管理动态分配的资源,比如在堆上分配的内存。
#include <iostream>
#include <cstring>
class MyClass {
private:
char* buffer;
public:
// 构造函数
MyClass(const char* str) {
if (str) {
buffer = new char[strlen(str) + 1];
strcpy(buffer, str);
} else {
buffer = nullptr;
}
}
// 析构函数
~MyClass() {
delete[] buffer;
}
// 拷贝构造函数
MyClass(const MyClass& other) {
if (other.buffer) {
buffer = new char[strlen(other.buffer) + 1];
strcpy(buffer, other.buffer);
} else {
buffer = nullptr;
}
}
// 拷贝赋值运算符
MyClass& operator=(const MyClass& other) {
if (this != &other) {
delete[] buffer; // 首先删除当前对象的资源
if (other.buffer) {
buffer = new char[strlen(other.buffer) + 1];
strcpy(buffer, other.buffer);
} else {
buffer = nullptr;
}
}
return *this;
}
};
int main() {
MyClass obj1("Hello");
MyClass obj2 = obj1; // 调用拷贝构造函数
MyClass obj3("World");
obj3 = obj1; // 调用拷贝赋值运算符
return 0;
}在这个例子中,构造函数为成员变量 buffer 分配内存,并复制给定的字符串;析构函数释放 buffer 所占用的内存,以避免内存泄露;拷贝构造函数创建一个新对象作为另一个现有对象的副本,并为其分配新的内存,以避免多个对象共享同一内存;拷贝赋值运算符更新对象时,首先释放原有资源,然后根据新对象的状态分配新资源。
这个类遵循规则三则,确保了动态分配资源的正确管理,避免了内存泄露和浅拷贝问题。
1.4.5 避免不必要的拷贝
避免不必要的拷贝是 C++ 程序设计中的一个重要原则,尤其是在处理大型对象或资源密集型对象时。使用引用(包括常量引用)和移动语义(C++11 引入)是实现这一目标的两种常见方法。
1.4.5.1 使用引用传递对象
通过使用引用(尤其是常量引用)来传递对象,可以避免在函数调用时创建对象的副本。
#include <iostream>
#include <vector>
using namespace std;
class LargeObject {
// 假设这是一个占用大量内存的大型对象
};
void processLargeObject(const LargeObject& obj) {
// 处理对象,但不修改它
cout << "Processing object..." << endl;
}
int main() {
LargeObject myLargeObject;
processLargeObject(myLargeObject); // 通过引用传递,避免拷贝
return 0;
}在这个例子中, processLargeObject 函数接受一个对 LargeObject 类型的常量引用,避免了在函数调用时复制整个 LargeObject 。
1.4.5.2 使用移动语义
C++11 引入了移动语义,允许资源(如动态分配的内存)的所有权从一个对象转移到另一个对象,这避免了不必要的拷贝。
#include <iostream>
#include <utility> // 对于 std::move
using namespace std;
class MovableObject {
public:
MovableObject() {
// 构造函数
}
MovableObject(const MovableObject& other) {
// 拷贝构造函数(可能很昂贵)
}
MovableObject(MovableObject&& other) noexcept {
// 移动构造函数(轻量级)
// 转移资源的所有权
}
MovableObject& operator=(MovableObject&& other) noexcept {
// 移动赋值运算符
// 转移资源的所有权
return *this;
}
};
MovableObject createObject() {
MovableObject obj;
return obj; // 返回时使用移动语义,而非拷贝
}
int main() {
MovableObject obj = createObject(); // 使用移动构造函数
return 0;
}在这个例子中, MovableObject 类有一个移动构造函数和一个移动赋值运算符,它们允许对象的资源(如动态分配的内存)在赋值或返回时被“移动”而非复制。这减少了对资源的不必要拷贝,提高了效率。通过这些方法,可以在 C++ 程序中有效地减少不必要的对象拷贝,尤其是对于大型或资源密集型的对象。
1.4.6 拷贝构造函数的隐式调用
在C++ 中,拷贝构造函数可能会在几种不明显的情况下被隐式调用。这种隐式调用通常发生在对象需要被复制时,但代码中并没有明显的赋值或构造函数调用。了解这些情况对于高效和正确地管理资源非常重要。
1.4.6.1 作为函数参数传递(按值传递)
当对象作为函数参数按值传递时,会调用拷贝构造函数来创建参数的本地副本。
#include <iostream>
using namespace std;
class MyClass {
public:
MyClass() {}
MyClass(const MyClass &) {
cout << "拷贝构造函数被隐式调用" << endl;
}
};
void function(MyClass obj) {
// 对 obj 的操作
}
int main() {
MyClass myObject;
function(myObject); // 调用 function 时,拷贝构造函数被隐式调用
return 0;
}1.4.6.2 从函数返回对象(按值返回)
当函数返回一个对象时,拷贝构造函数会被用于创建返回值的副本。
MyClass function() {
MyClass tempObject;
return tempObject; // 返回时,拷贝构造函数被隐式调用
}
int main() {
MyClass myObject = function(); // 接收返回值时可能还会有一次拷贝(或移动)
return 0;
}1.4.6.3 初始化另一个对象
当用一个对象初始化另一个同类型的新对象时,会使用拷贝构造函数。
int main() {
MyClass obj1;
MyClass obj2 = obj1; // 初始化时,拷贝构造函数被隐式调用
return 0;
}在所有这些情况下,如果类包含资源管理(例如,动态内存分配),那么正确地实现拷贝构造函数是非常重要的,以确保资源的正确复制和管理,防止潜在的内存泄漏或其他问题。此外,随着 C++11 的引入,移动语义提供了对资源的高效管理方式,可以减少这些场景中的资源复制。
1.4.7 禁用拷贝构造函数
在C++ 中,禁用拷贝构造函数是一种常用的做法,尤其是在设计那些不应该被复制的类时。这可以通过将拷贝构造函数声明为 private 或使用 C++11 引入的 delete 关键字来实现。这样做的目的是防止类的对象被拷贝,从而避免可能导致的问题,如资源重复释放、无意义的资源复制等。
1.4.7.1 使用 delete 关键字
在 C++11 及更高版本中,可以使用 delete 关键字明确指定不允许拷贝构造,这种方法清晰明了,它向编译器和其他程序员直接表明该类的对象不能被拷贝。
class NonCopyable {
public:
NonCopyable() = default; // 使用默认构造函数
// 禁用拷贝构造函数
NonCopyable(const NonCopyable&) = delete;
// 禁用拷贝赋值运算符
NonCopyable& operator=(const NonCopyable&) = delete;
};
int main() {
NonCopyable obj1;
// NonCopyable obj2 = obj1; // 编译错误,拷贝构造函数被禁用
return 0;
}1.4.7.2 使用 private 声明(C++98/03)
在C++11 之前,常见的做法是将拷贝构造函数和拷贝赋值运算符声明为 private ,并且不提供实现:
class NonCopyable {
private:
// 将拷贝构造函数和拷贝赋值运算符设为私有
NonCopyable(const NonCopyable&);
NonCopyable& operator=(const NonCopyable&);
public:
NonCopyable() {}
};
int main() {
NonCopyable obj1;
// NonCopyable obj2 = obj1; // 编译错误,因为无法访问私有的拷贝构造函数
return 0;
}在这个例子中,任何尝试拷贝 NonCopyable 类型对象的操作都会导致编译错误,因为拷贝构造函数和拷贝赋值运算符是私有的,外部代码无法访问它们。
通过这些方法,可以确保类的对象不会被意外地拷贝,从而避免可能出现的资源管理相关的错误。
1.4.8 小结
在C++ 中拷贝构造函数需要注意的要点:
| 要点 | 描述 |
|
定义和作用
|
拷贝构造函数在创建对象作为另一个现有对象副本时调用,
通常有一个对同
类型对象的常量引用参数。
|
|
语法
|
典型声明为
ClassName(const ClassName &other)
。
|
|
深拷贝与浅拷贝
|
浅拷贝复制值,深拷贝创建资源的独立副本。对于包含指针的类,深拷贝通常必要。
|
|
规则三则
(Rule of
Three)
|
如果实现了拷贝构造函数、拷贝赋值运算符或析构函数中的任何一个,通常应该实现所有三个。
|
|
避免不必要的拷贝
|
对于大型对象,使用移动语义避免不必要的拷贝,并在传递对象时使用引用或指针。
|
|
拷贝构造函数的隐 式调用
|
不仅在显式复制时调用,也可能在将对象作为函数参数传递、从函数返回对象时隐式调用。
|
|
禁用拷贝构造函数
|
对于某些类,可以通过将拷贝构造函数声明为私有或使用
delete
关键字 禁用拷贝。
|
1.5 this 关键字
在C++ 中, this 关键字是一个指向调用对象的指针。它在成员函数内部使用,用于引用调用该函数的对象。使用 this 可以明确指出成员函数正在操作的是哪个对象的数据成员。下面是一个使用 Car 类来展示 this 关键字用法的示例:
#include <iostream>
#include <string>
using namespace std;
class Car {
private:
string brand;
int year;
public:
Car(string brand, int year) {
this->brand = brand;
this->year = year;
// cout << "构造函数中:" << endl;
// cout << this << endl;
}
void display() const {
cout << "Brand: " << this->brand << ", Year: " << this->year << endl;
// 也可以不使用 this->,直接写 brand 和 year
}
Car& setYear(int year) {
this->year = year; // 更新年份
return *this; // 返回调用对象的引用
}
};
int main()
{
Car car("宝马",2024);
car.display();
// 链式调用
car.setYear(2023).display();
// cout << "main函数中:" << endl;
// cout << &car << endl;
// Car car2("宝马",2024);
// cout << "main函数中:" << endl;
// cout << &car2 << endl;
return 0;
}在这个例子中, Car 类的构造函数使用 this 指针来区分成员变量和构造函数参数。同样, setYear成员函数使用 this 指针来返回调用该函数的对象的引用,这允许链式调用,如myCar.setYear(2021).display(); 。在 main 函数中创建了 Car 类型的对象,并展示了如何使用这些成员函数。
1.6 new/delete 关键字
在C++中, new 关键字用于动态分配内存。它是C++中处理动态内存分配的主要工具之一,允许在程序运行时根据需要分配内存。
基本用法:
(1)分配单个对象:使用 new 可以在堆上动态分配一个对象。例如, new int 会分配一个 int 类型的空间,并返回一个指向该空间的指针。
int* ptr = new int; //C语言中,int *p = (int *)malloc(sizeof(int));(2)分配对象数组: new 也可以用来分配一个对象数组。例如, new int[10] 会分配一个包含10个整数的 数组。
int* arr = new int[10]; //C语言中,int *arr = (int *)malloc(sizeof(int)*10);(3)初始化:可以在 new 表达式中使用初始化。对于单个对象,可以使用构造函数的参数。
MyClass* obj = new MyClass(arg1, arg2);在使用 new 分配的内存必须显式地通过 delete (对于单个对象)或 delete[] (对于数组)来释放,以避免内存泄露:
(1)释放单个对象:
delete ptr; // 释放 ptr 指向的对象(2)释放数组:
delete[] arr; // 释放 arr 指向的数组注:(1)异常安全:如果 new 分配内存失败,它会抛出 std::bad_alloc 异常(除非使用了 nothrow 版本);
(2)内存泄露:忘记释放使用 new 分配的内存会导致内存泄露;
(3)匹配使用 delete 和 delete[] :为避免未定义行为,使用 new 分配的单个对象应该使用delete 释放,使用 new[] 分配的数组应该使用 delete[] 释放。
class MyClass {
public:
MyClass() {
std::cout << "Object created" << std::endl;
}
};
int main() {
// 分配单个对象
MyClass* myObject = new MyClass();
// 分配对象数组
int* myArray = new int[5]{1, 2, 3, 4, 5};
// 使用对象和数组...
// 释放内存
delete myObject;
delete[] myArray;
return 0;
}在这个例子中, new 被用来分配一个 MyClass 类型的对象和一个整数数组,然后使用 delete 和delete[] 来释放内存。每个 new 都对应一个 delete ,保证了动态分配的内存被适当管理。
2、析构函数
析构函数是C++中的一个特殊的成员函数,它在对象生命周期结束时被自动调用,用于执行对象销毁前的清理工作。析构函数特别重要,尤其是在涉及动态分配的资源(如内存、文件句柄、网络连接等)的情况下。
基本特性:
(1)名称:析构函数的名称由波浪号( ~ )后跟类名构成,如 ~MyClass() 。
(2)无返回值和参数:析构函数不接受任何参数,也不返回任何值。
(3)自动调用:当对象的生命周期结束时(例如,一个局部对象的作用域结束,或者使用 delete 删除一个动态分配的对象),析构函数会被自动调用。
(4)不可重载:每个类只能有一个析构函数。
(5)继承和多态:如果一个类是多态基类,其析构函数应该是虚的。
#include <iostream>
using namespace std;
class MyClass{
private:
int* datas;
public:
MyClass(int size){
datas = new int[size];
}
~MyClass(){
cout << "析构函数被调用" << endl;
delete[] datas;
}
};
int main()
{
MyClass m1(5);
MyClass *m2 = new MyClass(10);
delete m2;
return 0;
}在这个示例中, MyClass 的构造函数分配了一块内存,而析构函数释放了这块内存。当 obj 的生命周期结束时(即离开了它的作用域), MyClass 的析构函数被自动调用,负责清理资源,防止内存泄露。
析构函数在管理资源方面非常重要。没有正确实现析构函数,可能导致资源泄露或其他问题。在基于RAII(资源获取即初始化)原则的C++编程实践中,确保资源在对象析构时被适当释放是非常关键的。当使用智能指针和其他自动资源管理技术时,可以减少显式编写析构函数的需要,但了解析构函数的工作原理仍然很重要。
关于析构函数的要点:
|
要点
|
描述
|
|
定义和作
用
|
析构函数在对象生命周期结束时自动调用,用于清理对象可能持有的资源。
|
|
语法
|
析构函数名称由波浪线
(~)
后跟类名构成,例如
MyClass
的析构函数为~MyClass() 。
|
|
资源管理
|
用于释放对象在生命周期中分配的资源,如动态内存、文件句柄、网络连接等。
|
|
自动调用机制
|
当对象离开其作用域或通过
delete
删除时,将自动调用其析构函数。
|
|
防止资源
泄露
|
正确实现析构函数对防止资源泄露至关重要,特别是在涉及动态资源分配的情况。
|
|
虚析构函数
|
如果类作为基类设计,应有一个虚析构函数,以确保正确调用派生类的析构函数。
|
|
析构函数与异常
|
析构函数不应抛出异常,如果可能抛出,应在函数内捕获。
|
|
删除的析构函数
|
可以通过将析构函数声明为删除(
~MyClass() = delete;
)来禁止删除某类对象。
|
|
与构造函
数的关系
|
每个类只能有一个析构函数,不可重载,与构造函数相比。
|
|
规则三则/
五则
|
如果类需要自定义析构函数、拷贝构造函数或拷贝赋值运算符,可能也需要自定义另外两个(规则三则)。在 C++11
后还包括移动构造函数和移动赋值运算符(规则五则)。
|
3、静态成员
3.1 静态成员的定义
静态成员在C++类中是一个重要的概念,它包括静态成员变量和静态成员函数。静态成员的特点和存在的意义如下:
静态成员变量:
(1)定义:静态成员变量是类的所有对象共享的变量。与普通成员变量相比,无论创建了多少个类的实例,静态成员变量只有一份拷贝。
(2)初始化:静态成员变量需要在类外进行初始化,通常在类的实现文件中。
(3)访问:静态成员变量可以通过类名直接访问,不需要创建类的对象。也可以通过类的对象访问。
(4)用途:常用于存储类级别的信息(例如,计数类的实例数量)或全局数据需要被类的所有实例共享。
静态成员函数:
(1)定义:静态成员函数是可以不依赖于类的实例而被调用的函数。它不能访问类的非静态成员变量和非静态成员函数。
(2)访问:类似于静态成员变量,静态成员函数可以通过类名直接调用,也可以通过类的实例调用。
(3)用途:常用于实现与具体对象无关的功能,或访问静态成员变量。
class MyClass {
public:
static int staticValue; // 静态成员变量
MyClass() {
// 每创建一个对象,静态变量增加1
staticValue++;
}
static int getStaticValue() {
// 静态成员函数
return staticValue;
}
};
// 类外初始化静态成员变量
int MyClass::staticValue = 0;
int main() {
MyClass obj1, obj2;
std::cout << MyClass::getStaticValue(); // 输出2
}静态成员的优点:
(1)共享数据:允许对象之间共享数据,而不需要每个对象都有一份拷贝。
(2)节省内存:对于频繁使用的类,使用静态成员可以节省内存。
(3)独立于对象的功能:静态成员函数提供了一种在不创建对象的情况下执行操作的方法,这对于实现工具函数或管理类级别状态很有用。
3.2 静态成员变量的作用
静态成员变量在C++中的一个典型应用是用于跟踪类的实例数量。这个案例体现了静态成员变量的特性:它们在类的所有实例之间共享,因此适合于存储所有实例共有的信息。
#include <iostream>
using namespace std;
class Myclass{
private:
static int staticNumofInstance;
public:
Myclass(){
staticNumofInstance++;
}
~Myclass(){
staticNumofInstance--;
}
static int getNunofInstance(){
return staticNumofInstance;
}
};
int Myclass::staticNumofInstance = 0;
int main()
{
Myclass m1;
cout << Myclass::getNunofInstance() << endl;
Myclass m2;
cout << m2.getNunofInstance() << endl;
{
Myclass m3;
cout << Myclass::getNunofInstance() << endl;
Myclass m4;
cout << Myclass::getNunofInstance() << endl;
}
cout << Myclass::getNunofInstance() << endl;
Myclass *m5 = new Myclass;
cout << Myclass::getNunofInstance() << endl;
delete m5;
cout << Myclass::getNunofInstance() << endl;
return 0;
}在这个例子中: Myclass 类有一个静态成员变量 staticNumofInstance ,用来跟踪该类的实例数量。每当创建 Myclass 的新实例时,构造函数会增加 staticNumofInstance 。每当一个 Myclass 实例被销毁时,析构函数会减少 staticNumofInstance 。通过静态成员函数 getNunofInstance 可以随时获取当前的实例数量。静态成员变量 staticNumofInstance 在类外初始化为0。
这个案例展示了静态成员变量如何在类的所有实例之间共享,并为所有实例提供了一个共同的状态(在这个例子中是实例的数量)。这种技术在需要跟踪对象数量或实现某种形式的资源管理时特别有用。